0of18read0 XP
Use Python packages (spaCy, NumPy, Keras, etc.) to implement specific traditional machine learning analyses.
Apply spaCy, NumPy, and Keras to implement traditional machine learning workflows (e.g., text tokenization, numerical transformations, neural network training) in accordance with exam task 4.6[^1][^2].
- Time
- 20–25 min
- Type
- exercise
- Bloom
- Apply → Create
- XP
- 100
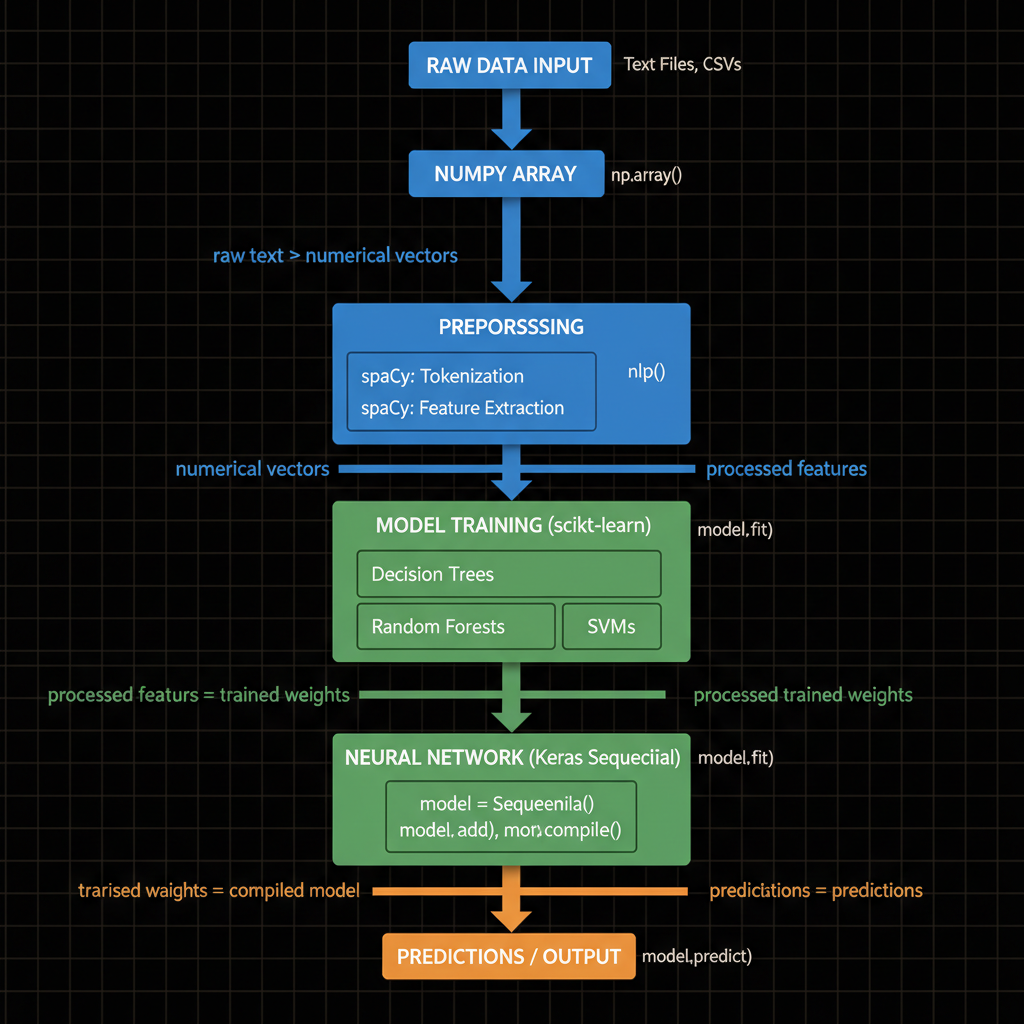
Architecture diagram for Use Python packages (spaCy, NumPy, Keras, etc.) to implement specific traditional machine learning analyses.. The traditional machine learning pipeline using Python packages. At the top, show raw data input feeding into a NumPy array icon. This flows down to a preprocessing stage with spaCy for text tokenization and feature extraction. Next, the processed features move into a scikit-learn box containing model training algorithms (decision trees, random forests, SVMs). Below that, show a Keras sequential model block for neural network implementation. Each stage should be connected by bold arrows labeled with data transformations (raw text, numerical vectors, trained weights, predictions). Use blue for data processing stages, green for model training, and orange for output predictions. Include small code snippet labels like "np.array()" and "model.fit()" beside relevant boxes to indicate the actual package methods used at each step.
You'll be able to
- Apply spaCy, NumPy, and Keras to implement traditional machine learning workflows (e.g., text tokenization, numerical transformations, neural network training) in accordance with exam task 4.6[^1][^2].
- Evaluate the appropriateness of specific Python packages (spaCy for natural language processing, NumPy for array operations, Keras for deep learning) for given traditional machine learning analysis tasks, referencing the capabilities outlined in exam tasks 1.6 and 4.3[^3][^4][^5].
- Create end-to-end traditional machine learning pipelines that integrate multiple Python packages (data preprocessing with NumPy, feature extraction with spaCy, model training with Keras) to solve domain-specific problems aligned with NVIDIA certification objectives[^6].
- Classify traditional machine learning analysis requirements by matching them to the correct Python package ecosystem, demonstrating familiarity with package capabilities as required by exam domain 4[^1][^2].
Key concepts · tap to reveal
1/18·Idea
0%
Idea
01 / 18
The Production ML Challenge
You're three days from deploying a sentiment-analysis pipeline that will classify 500,000 customer support tickets per day, and your manager just asked you to prove the model works before it touches production data. The NVIDIA certification exam expects you to reach for packages like spaCy for text preprocessing, NumPy for numerical operations, and Keras for building the classifier[^1][^6], but knowing which package solves which part of the pipeline separates candidates who pass from those who guess.
Your task Write a prompt that asks Claude to recommend the right AI setup for a real task you're facing — then weigh its answer against this lesson, "Use Python packages (spaCy, NumPy, Keras, etc.) to implement specific traditional machine learning analyses.."
a strong prompt:role · context · task · format · example
Exercise · scenario
## Scenario Your team is building a sentiment-analysis pipeline to classify customer support tickets before they reach a generative AI summarization stage. The lead engineer proposes using spaCy for named-**entity recognition**, NumPy for feature normalization, and Keras to train a shallow neural network on 50,000 labeled tickets[^1][^6]. A junior developer suggests skipping traditional ML entirely and feeding raw text directly into a large language model API. You must decide which approach aligns with the exam objective to implement specific traditional machine learning analyses using the named Python packages[^1][^2], balancing cost, interpretability, and the requirement to demonstrate foundational ML skills in an NVIDIA certification context[^6].
Deliverable
You will produce a **Traditional ML Pipeline Notebook** that demonstrates your ability to implement at least three distinct machine learning analyses using the Python packages covered in this lesson (spaCy, NumPy, Keras, or similar libraries aligned with the NVIDIA exam objectives[^1][^6]).
Practice · Scenarios
0 of 8 revealed
Scenario 1 of 8
A municipal government is classifying 10,000 citizen complaint tickets into 12 categories (noise, potholes, graffiti, etc.). Historical labeled data shows complex non-linear patterns that logistic regression cannot capture. The IT department has TensorFlow installed and wants a feedforward neural network with dropout regularization and early stopping. Input features are already vectorized as 150-dimensional arrays, and the team needs to define custom loss functions and training callbacks.
Sources
- [1]NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide·NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide (2026) · Vendor
- [2]NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide·NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide (2026) · Vendor
- [3]AWS Well-Architected Framework: Machine Learning Lens·AWS Well-Architected Framework: Machine Learning Lens (2026) · Vendor
Submit your work for review
Paste your capstone artifact below. You'll get back a 4-level rubric grade, per-criterion feedback, and three concrete edits to strengthen it.