0of20read0 XP
Curate and embed content datasets for RAGs.
Curate appropriate content datasets for retrieval-augmented generation systems by selecting, cataloging, and preparing source materials that align with domain requirements and quality standards[^1][^4].
- Time
- 20–25 min
- Type
- exercise
- Bloom
- Apply → Create
- XP
- 100
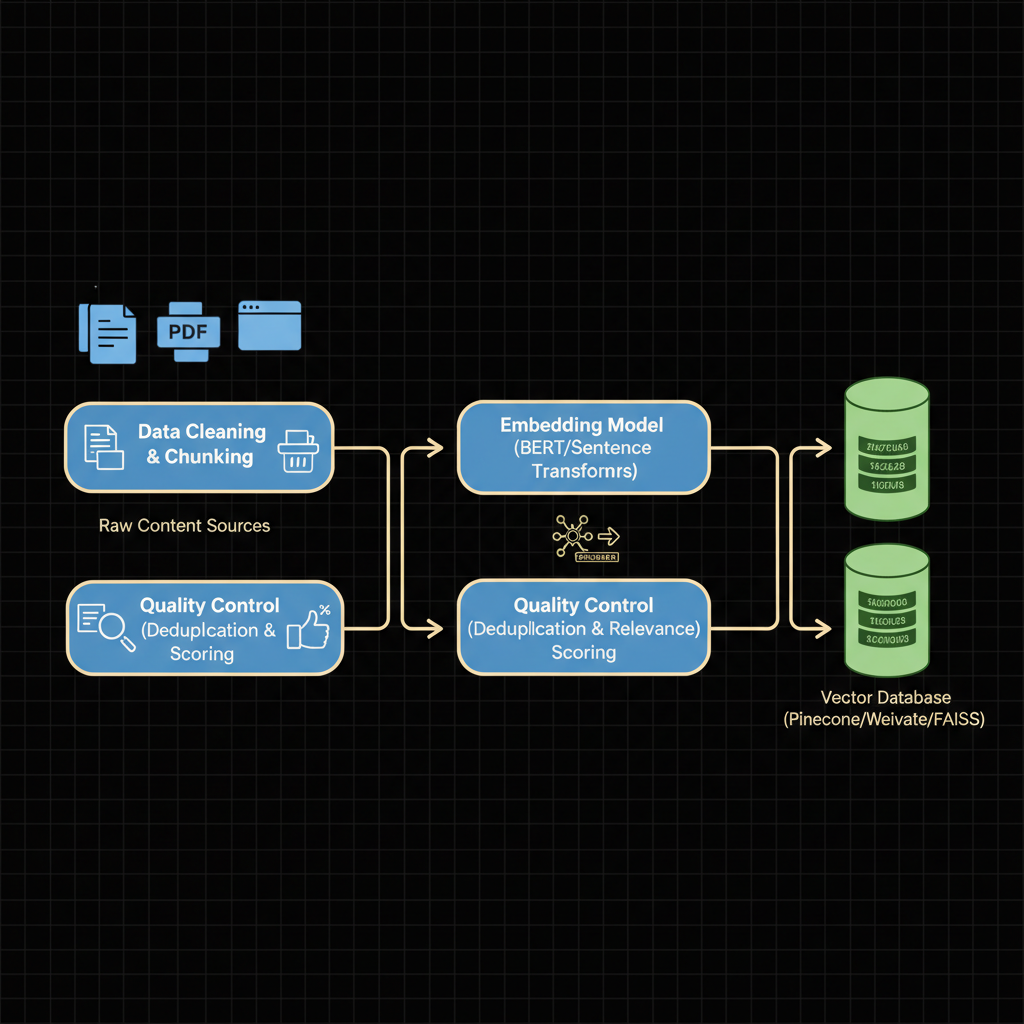
Architecture diagram for Curate and embed content datasets for RAGs.. The RAG content curation and embedding pipeline from left to right. Begin with raw content sources (documents, PDFs, web pages) flowing into a data cleaning and chunking stage, then to an embedding model (like BERT or sentence transformers) that converts text chunks into vector representations. Show these vectors being stored in a vector database (Pinecone, Weaviate, or FAISS). Include a parallel quality control branch checking for duplicate content and relevance scoring. Use arrows to indicate data flow direction, label each processing stage clearly, and add small icons representing documents transforming into numerical vectors. Use blue for data processing nodes and green for storage components to distinguish pipeline stages.
You'll be able to
- Curate appropriate content datasets for retrieval-augmented generation systems by selecting, cataloging, and preparing source materials that align with domain requirements and quality standards[^1][^4].
- Apply embedding techniques to transform curated content into vector representations suitable for semantic search and retrieval within RAG architectures[^1][^6][^7].
- Evaluate the completeness and relevance of curated datasets against RAG use-case requirements, identifying gaps in coverage or quality that may affect retrieval performance[^1][^3].
- Create a production-ready content pipeline that processes raw documents into embedded representations, ensuring consistency, discoverability, and interoperability across RAG system components[^1][^4].
Key concepts · tap to reveal
1/20·Idea
0%
Idea
01 / 20
When curation failures become legal liabilities
You're three weeks into deploying a customer-support chatbot when the VP of Operations walks into your cube with a printout of user complaints: the bot is confidently citing policies that were retired six months ago, and two customers have already escalated to legal. The root cause isn't the model; it's the 47,000 unvetted PDF pages, overlapping SharePoint folders, and three separate wiki instances you dumped into the retrieval index without a curation plan. Retrieval-Augmented Generation systems promise to ground large language models in your organization's real documents, but research shows that even state-of-the-art architectures fail when the underlying knowledge base is stale, contradictory, or poorly embedded.
Your task Write a prompt that asks Claude to recommend the right AI setup for a real task you're facing — then weigh its answer against this lesson, "Curate and embed content datasets for RAGs.."
a strong prompt:role · context · task · format · example
Exercise · scenario
## Scenario (Applied) You are building a **retrieval-augmented generation** system for a corporate **knowledge base** containing product manuals, internal wikis, and customer support transcripts. Your manager asks you to include the company's competitor analysis reports—documents marked confidential and licensed only for internal strategic review—in the RAG corpus so the chatbot can answer questions about market positioning. The reports are well-structured, highly relevant to sales inquiries, and would significantly improve response quality. However, the original licensing terms restrict derivative use, and your **embedding** process will transform the text into **vector representations** stored in a third-party managed service [^1][^4]. **What would you do, and why?** *(Difficulty: Applied)*
Deliverable
You will produce a **RAG Dataset Curation Plan** as a structured Markdown document that specifies the end-to-end workflow for preparing a domain-specific corpus for **retrieval-augmented generation**[^1]. Your plan must define the source data inventory (file types, locations, and licensing constraints), the chunking and **embedding** strategy (chunk size, overlap, and embedding model selection), the vector store configuration (index type and distance metric), and a three-query test suite with expected retrieval results that validate your pipeline[^1][^3].
Practice · Scenarios
0 of 8 revealed
Scenario 1 of 8
An e-commerce platform is building a product recommendation RAG to answer customer questions about electronics specifications. The corpus includes 200,000 product descriptions scraped from manufacturer websites. Testing reveals that queries like 'laptop with 16GB RAM under $1000' return products with incorrect specifications or prices. Product descriptions were embedded as-is without cleaning, and some contain HTML artifacts, promotional language, and outdated pricing. What is the MOST critical curation step to improve retrieval accuracy?
Sources
- [1]NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide·NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide (2026) · Vendor
- [2]arXiv API·arXiv API (2026) · Research
- [3]arXiv API·arXiv API (2026) · Research
- [4]AWS Bedrock Developer / User Guide·AWS Bedrock Developer / User Guide (2026) · Vendor
Submit your work for review
Paste your capstone artifact below. You'll get back a 4-level rubric grade, per-criterion feedback, and three concrete edits to strengthen it.