0of20read0 XP
Select and use models to create text embeddings.
Select an appropriate embedding model from available foundation model providers based on vector dimension requirements, normalization options, and compatibility with target vector store infrastructure [^2][^4].
- Time
- 20–25 min
- Type
- exercise
- Bloom
- Apply → Create
- XP
- 100
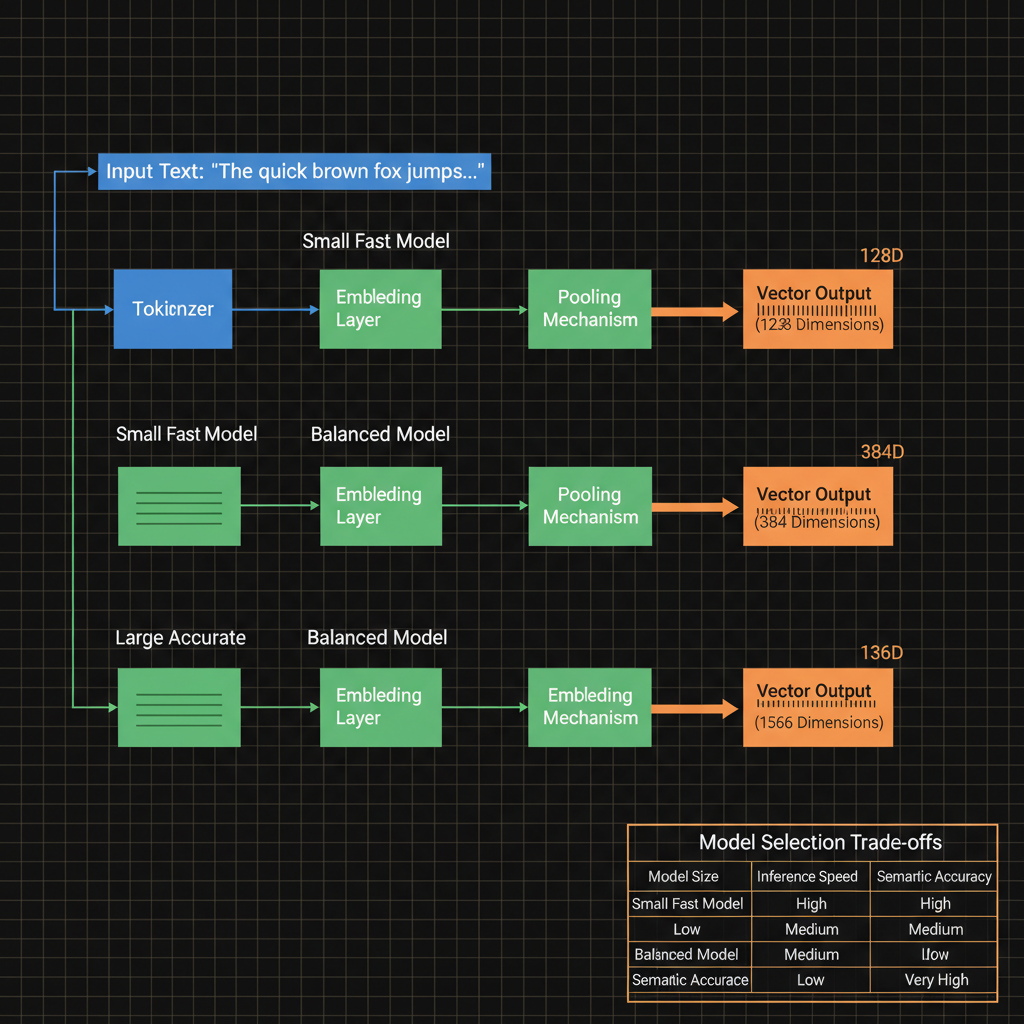
Architecture diagram for Select and use models to create text embeddings.. The text embedding pipeline from input to vector output. Display a sample text string entering from the left, passing through a transformer-based embedding model (represented as a neural network block with multiple layers), and outputting as a high-dimensional vector array on the right. Include three parallel example paths showing different embedding models: a small fast model (128 dimensions), a balanced model (384 dimensions), and a large accurate model (1536 dimensions). Label key components: tokenizer, embedding layer, pooling mechanism, and final vector representation. Use blue for the input text, green for model processing blocks, and orange for output vectors. Add dimension annotations and a small comparison table showing trade-offs between model size, speed, and semantic accuracy for model selection decisions.
You'll be able to
- Select an appropriate embedding model from available foundation model providers based on vector dimension requirements, normalization options, and compatibility with target vector store infrastructure [^2][^4].
- Apply embedding model APIs to convert text inputs into vector representations, configuring model-specific parameters such as dimensionality and normalization settings [^5].
- Evaluate embedding model outputs by interpreting response fields including embedding arrays, token counts, and error messages to verify successful vector generation [^7].
- Create vector store configurations that align embedding model outputs with required schema fields for vectors, text chunks, and metadata to support retrieval operations [^2].
- Implement programmatic queries against vector-indexed knowledge bases using text inputs, interpreting retrieval results that include relevance scores and source references [^3].
Key concepts · tap to reveal
1/20·Idea
0%
Idea
01 / 20
The Embeddings Problem
You're building a retrieval-augmented generation system for customer support. Your product team wants users to ask questions in natural language and receive answers grounded in your company's 50,000-page technical documentation. You spin up a vector database, dump in raw text files, and run your first query: "How do I reset my password?" The system returns a chunk about network protocols and another about billing cycles. Nothing about passwords. Your vector store is live, your LLM is ready, but without the right embedding model converting queries and documents into comparable numerical representations, your search results are random noise.
Your task Write a prompt that asks Claude to recommend the right AI setup for a real task you're facing — then weigh its answer against this lesson, "Select and use models to create text embeddings.."
a strong prompt:role · context · task · format · example
Exercise · scenario
## Scenario (Applied) Your team is building a retrieval-augmented generation (RAG) pipeline for a manufacturing knowledge base that includes equipment manuals, safety protocols, and video training content. The data science lead proposes using Amazon Titan Text Embeddings V2 for all content types because it is already approved and integrated into your AWS Bedrock environment [^4][^5]. However, the corpus includes both textual documents and video files with embedded speech and visual diagrams. A colleague suggests that a multimodal embeddings model may be necessary to handle the video content effectively, while another argues that extracting transcripts and processing them as text will be simpler and sufficient for the current use case [^7]. **What would you do, and why?**
Deliverable
You will produce a **markdown document** named `embedding-model-comparison.md` that compares at least three text embedding models supported by a major cloud platform (AWS Bedrock, Azure OpenAI, or NVIDIA NIM). For each model, document the model ID, provider, supported vector dimensions, **normalization** options (if applicable), and one concrete use-case scenario (retrieval, semantic search, or knowledge base indexing) [^4][^5].
Practice · Scenarios
0 of 8 revealed
Scenario 1 of 8
An e-commerce platform with 10 million product listings is implementing semantic search to improve customer discovery. Currently, keyword search returns poor results when customers use colloquial terms or describe products functionally rather than by exact product names. The ML team must choose between using a pre-trained multilingual embedding model that supports 50+ languages, a retail-specific English model fine-tuned on product catalogs, or training a custom model on their proprietary catalog data. The platform operates in 12 countries, but 80% of traffic comes from English-speaking markets. Training a custom model would require 6 months and significant GPU resources, while pre-trained models can be deployed within weeks.
Sources
- [1]AWS Bedrock Developer / User Guide·AWS Bedrock Developer / User Guide (2026) · Vendor
- [2]NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide·NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide (2026) · Vendor
Submit your work for review
Paste your capstone artifact below. You'll get back a 4-level rubric grade, per-criterion feedback, and three concrete edits to strengthen it.