0of20read0 XP
Assist in the deployment and evaluations of model scalability, performance, and reliability under the supervision of senior
Apply deployment procedures for generative AI models while documenting scalability constraints and performance baselines under senior supervision, consistent with the task requirements in Domain 4 of the NCA-GENL exam [^1].
- Time
- 20–25 min
- Type
- exercise
- Bloom
- Apply → Evaluate
- XP
- 100
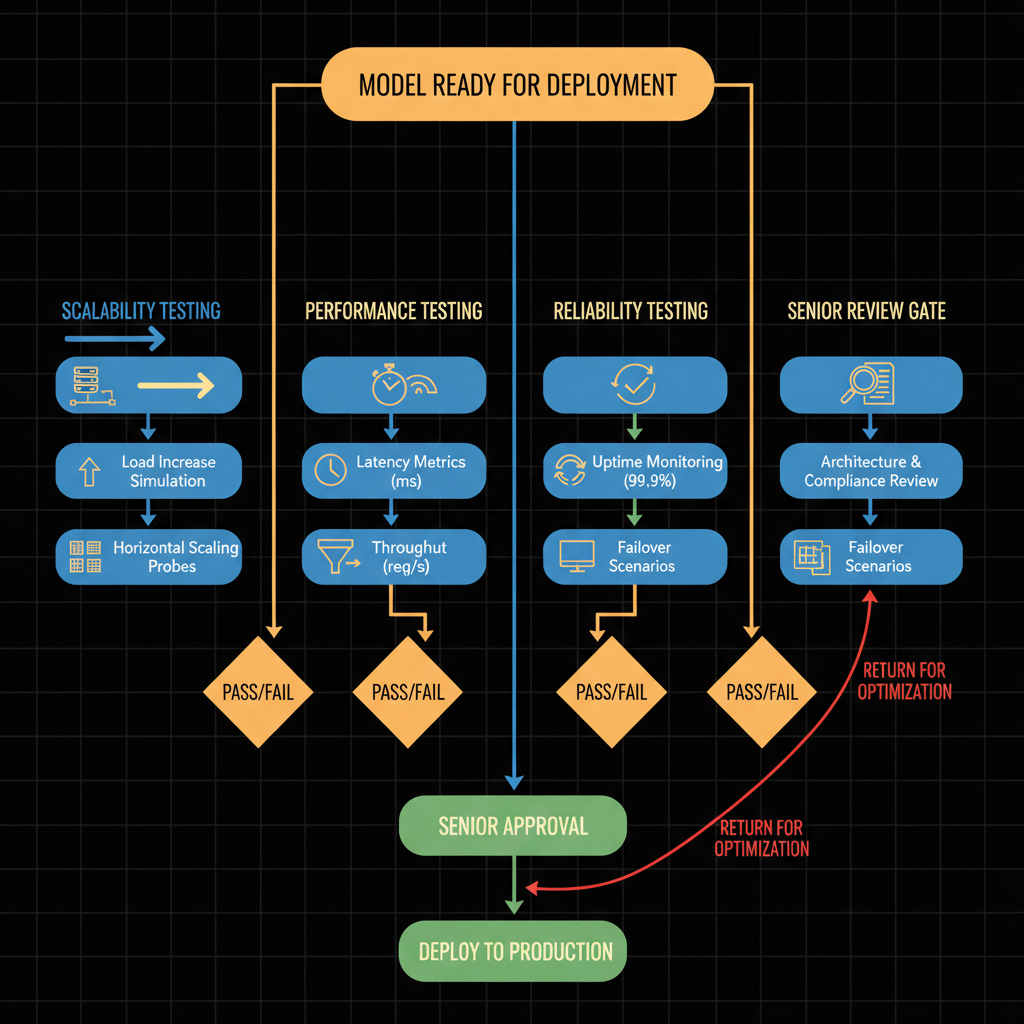
Architecture diagram for Assist in the deployment and evaluations of model scalability, performance, and reliability under the supervision of senior. **Diagram Brief:** Create a flowchart showing the supervised model deployment evaluation process. Start with "Model Ready for Deployment" at top, flowing through four parallel evaluation branches: Scalability Testing (load increase arrows, horizontal scaling icons), Performance Testing (latency/throughput metrics boxes), Reliability Testing (uptime monitoring, failover scenarios), and Senior Review Gate. Each branch contains 2-3 specific test activities with pass/fail decision diamonds. All branches converge at "Senior Approval" node, then split to either "Deploy to Production" (green path) or "Return for Optimization" (red path back to start). Use blue for testing phases, orange for decision points, green for approval, red for rejection. Include small icons representing compute resources, clocks for performance, and checkmarks for reliability metrics within respective branches.
You'll be able to
- Apply deployment procedures for generative AI models while documenting scalability constraints and performance baselines under senior supervision, consistent with the task requirements in Domain 4 of the NCA-GENL exam [^1].
- Evaluate model reliability metrics (latency, throughput, error rates) against production service-level objectives, identifying failure modes and proposing corrective actions for review by senior team members [^1][^3].
- Classify scalability bottlenecks in deployed generative AI systems by analyzing resource utilization patterns (GPU memory, compute throughput, network bandwidth) and mapping findings to architectural trade-offs [^1][^3].
- Execute performance evaluation protocols for large language models in supervised deployment scenarios, collecting quantitative metrics and preparing structured reports that support senior-led decision-making [^1][^3].
- Compare deployment configurations across development, staging, and production environments, explaining how changes in model serving infrastructure affect scalability, performance, and reliability outcomes under the guidance of senior engineers [^1].
Key concepts · tap to reveal
1/20·Idea
0%
Idea
01 / 20
When Deployment Evaluation Becomes Mission-Critical
You're three days into your first AI engineering role when your team lead drops a Slack message: "Customer demo in 48 hours. New LLM deployment is timing out under load. Can you help me trace whether it's a tokenizer bottleneck, a batching config issue, or something in the inference engine?" You stare at the monitoring dashboard, watching request latencies spike from 200 ms to 11 seconds. Your ability to systematically evaluate what's breaking and why will determine whether the demo succeeds or the customer walks. This is the moment where deployment evaluation skills stop being theoretical and start protecting revenue.
Your task Write a prompt that asks Claude to recommend the right AI setup for a real task you're facing — then weigh its answer against this lesson, "Assist in the deployment and evaluations of model scalability, performance, and reliability under the supervision of senior."
a strong prompt:role · context · task · format · example
Exercise · scenario
## Scenario (Applied) You are an associate ML engineer supporting a senior team member who is preparing to deploy a fine-tuned generative AI model for a customer-facing chatbot. During pre-deployment testing, you notice that response **latency** spikes above 2 seconds when concurrent user requests exceed 50, but the senior engineer has scheduled the production rollout for tomorrow morning. The senior asks you to document your observations and recommend whether to proceed with deployment, delay for further load testing, or implement request throttling as an interim measure[^1][^3]. What would you do, and why?
Deliverable
You will produce a **Deployment Evaluation Report** in Markdown format that documents your assisted role in assessing model **scalability**, performance, and reliability under senior supervision, directly aligned with the NCA-GENL exam objective [^1].
Practice · Scenarios
0 of 8 revealed
Scenario 1 of 8
A financial services firm deploys a contract analysis LLM to process legal documents. Your supervisor asks you to evaluate performance metrics after the first month. The system processes 2,000 documents daily with an average inference time of 4.3 seconds per document. However, you notice that 15% of documents (those exceeding 8,000 tokens) take an average of 18.7 seconds, while 85% of shorter documents average 2.1 seconds. The SLA requires 95% of requests to complete within 6 seconds. GPU utilization averages 62% but shows periodic spikes to 98% correlating with long-document processing. Classify the performance characteristic requiring optimization.
Sources
- [1]NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide·NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide (2026) · Vendor
- [2]NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide·NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide (2026) · Vendor
Submit your work for review
Paste your capstone artifact below. You'll get back a 4-level rubric grade, per-criterion feedback, and three concrete edits to strengthen it.