0of20read0 XP
Identify relationships and trends or any factors that could affect the results of research.
Evaluate relationships between data augmentation strategies and model accuracy improvements in transformer-based NLP workflows, citing specific techniques from NVIDIA's recommended training paths[^1][^2].
- Time
- 20–25 min
- Type
- exercise
- Bloom
- Apply → Create
- XP
- 100
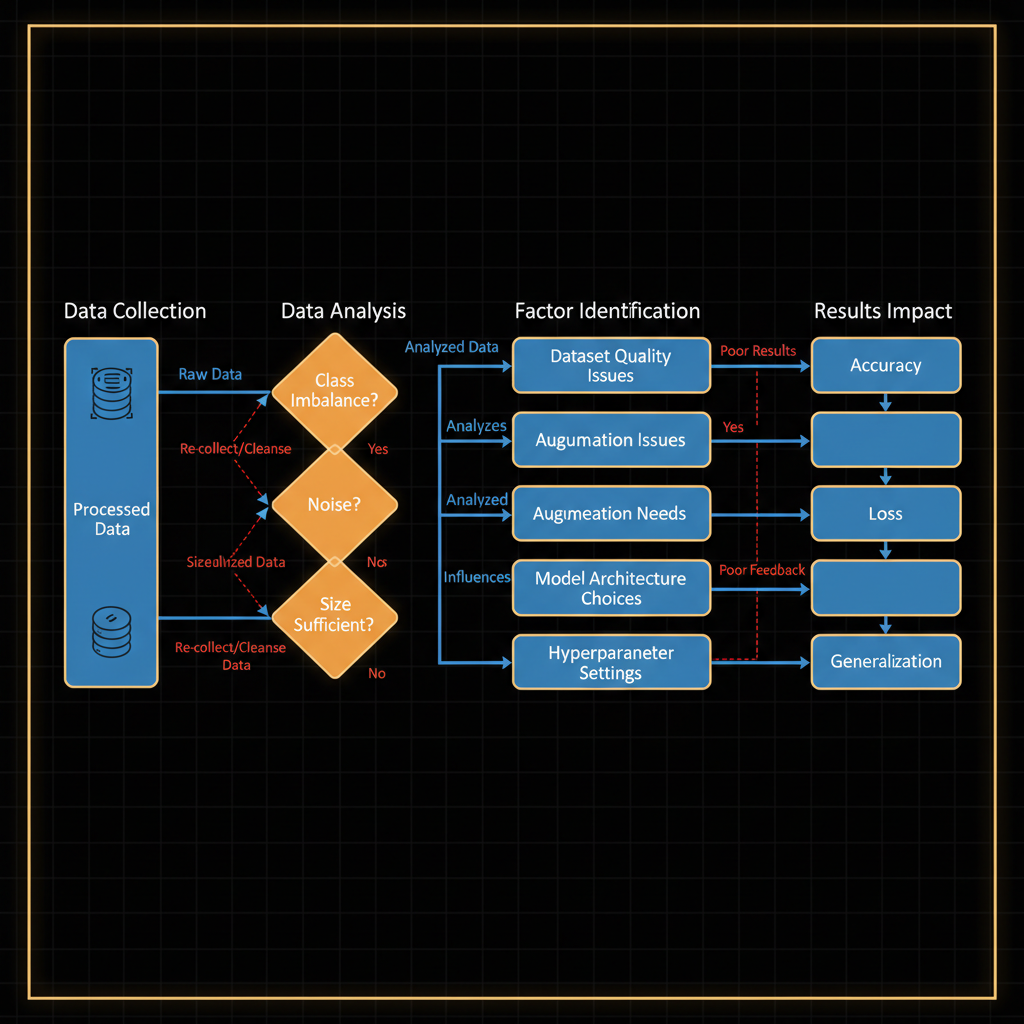
Architecture diagram for Identify relationships and trends or any factors that could affect the results of research.. The research analysis pipeline for identifying factors affecting deep learning results. The diagram should flow left to right with four main stages: Data Collection (raw dataset icon), Data Analysis (branching decision nodes checking for class imbalance, noise, and size sufficiency), Factor Identification (parallel boxes listing dataset quality issues, augmentation needs, model architecture choices, and hyperparameter settings), and Results Impact (arrows converging to show how each factor influences accuracy, loss, and generalization). Use blue for data stages, orange for analysis nodes, and red for negative impact indicators. Include labeled arrows between stages showing information flow and feedback loops where poor results trigger re-examination of earlier factors.
You'll be able to
- Evaluate relationships between data augmentation strategies and model accuracy improvements in transformer-based NLP workflows, citing specific techniques from NVIDIA's recommended training paths[^1][^2].
- Apply cuDF and RAPIDS acceleration libraries to analyze large-scale datasets for identifying trends that may influence generative AI research outcomes[^1].
- Classify factors that affect LLM performance across multiple NLP tasks (text classification, named-entity recognition, question-answering) by comparing pretrained model behaviors in controlled experiments[^1][^3].
- Construct LangChain-orchestrated data pipelines that surface relationships between input features and model outputs, enabling systematic identification of confounding variables in generative AI research[^1][^3].
- Evaluate the impact of transfer learning and zero-shot testing methodologies on research validity, distinguishing between model-intrinsic trends and dataset-driven artifacts[^3].
Key concepts · tap to reveal
1/20·Idea
0%
Idea
01 / 20
When Models Meet Reality
You've deployed a sentiment-analysis model that performed beautifully in testing, but three weeks into production your stakeholders report that customer complaints are being misclassified at an alarming rate. When you dig into the logs, you discover that a competitor launched a viral marketing campaign using slang your training data never included, and a seasonal product return spike has shifted the baseline tone of incoming messages. Spotting these hidden relationships—whether they emerge from data drift, cultural shifts, or pipeline dependencies—separates models that survive real-world deployment from those that fail silently.
Your task Write a prompt that asks Claude to recommend the right AI setup for a real task you're facing — then weigh its answer against this lesson, "Identify relationships and trends or any factors that could affect the results of research.."
a strong prompt:role · context · task · format · example
Exercise · scenario
## Scenario **Difficulty Level:** Applied You are a machine learning engineer preparing a named-entity recognition (NER) model for production deployment. During exploratory data analysis, you discover that 18% of your training corpus consists of financial documents from 2019–2020, while your target deployment environment will process real-time news articles and social media posts. Your senior engineer asks you to assess whether this distribution mismatch could affect model performance and to recommend next steps before moving to the experimentation phase. What would you do, and why? Consider how you would identify the relationship between training data characteristics and expected inference accuracy[^1], and which analysis tasks you might perform to quantify the risk[^1].
Deliverable
You will produce a **Research Trend Analysis Report** in Markdown format that documents relationships, trends, and confounding factors for a generative AI research question of your choice (for example, "Does fine-tuning a transformer model on domain-specific text improve named-entity recognition accuracy compared to zero-shot inference?").
Practice · Scenarios
0 of 8 revealed
Scenario 1 of 8
An e-commerce company is evaluating a text classification model to categorize customer support tickets into 15 product categories. During A/B testing, the model shows 84% accuracy overall, but analysis reveals category-level performance ranges from 95% (electronics) to 52% (home decor). The training dataset contains 45,000 electronics tickets, 38,000 apparel tickets, but only 3,200 home decor tickets. Furthermore, home decor tickets frequently mention multiple product types in a single inquiry (e.g., 'Does this lamp match your blue curtains?'), while electronics tickets typically focus on a single product. The model was trained using standard cross-entropy loss without class weighting.
Sources
- [1]NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide·NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide (2026) · Vendor
- [2]NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide·NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide (2026) · Vendor
Submit your work for review
Paste your capstone artifact below. You'll get back a 4-level rubric grade, per-criterion feedback, and three concrete edits to strengthen it.