0of22read0 XP
Familiarity with the capabilities of Python natural language packages (spaCy, NumPy, vector databases, etc.).
Classify the core capabilities of spaCy, NumPy, and vector databases according to their roles in natural language processing pipelines, distinguishing text preprocessing, numerical computation, and semantic search functions as defined in the NCA-GENL exam task body [^2].
- Time
- 20–25 min
- Type
- exercise
- Bloom
- Understand → Create
- XP
- 100
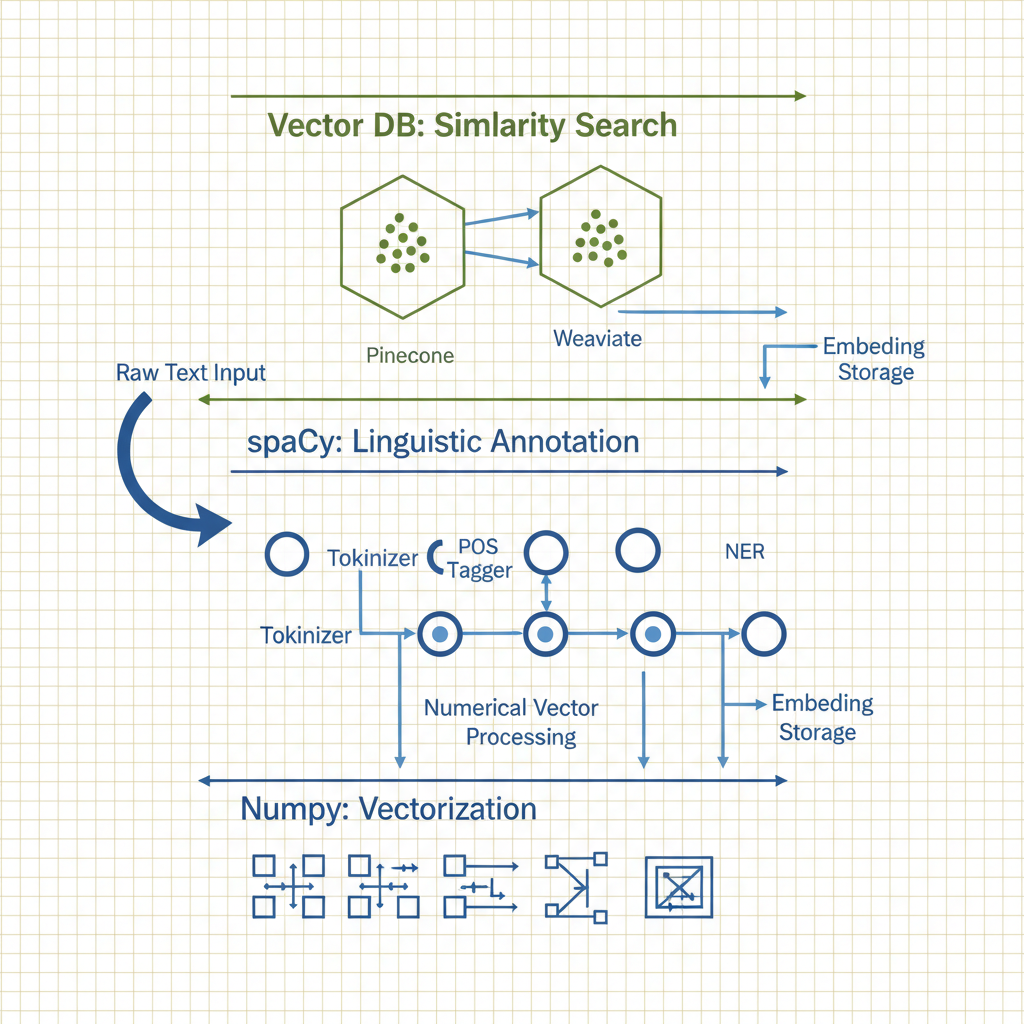
Architecture diagram for Familiarity with the capabilities of Python natural language packages (spaCy, NumPy, vector databases, etc.).. The Python NLP ecosystem stack. At the base layer, place NumPy providing numerical array operations with matrix icons. Middle layer shows spaCy with pipeline components (tokenizer, POS tagger, NER, dependency parser) connected by arrows. Top layer displays vector databases (Pinecone, Weaviate) storing embeddings as clustered points. Use directional arrows to show data flow: raw text enters spaCy, gets processed into numerical vectors via NumPy operations, then stored in vector databases. Label each component with primary capabilities (spaCy: linguistic annotation; NumPy: vectorization; vector DB: similarity search). Use blue tones for data processing layers and green for storage, with white background for clarity.
You'll be able to
- Classify the core capabilities of spaCy, NumPy, and vector databases according to their roles in natural language processing pipelines, distinguishing text preprocessing, numerical computation, and semantic search functions as defined in the NCA-GENL exam task body [^2].
- Apply Python natural language packages (spaCy, NumPy, vector databases) to implement specific traditional machine learning analyses in generative AI workflows, aligning with both familiarity (task 4.3) and implementation (task 4.6) requirements [^2][^4].
- Evaluate the suitability of different Python NLP packages for production NLP applications by comparing their performance characteristics, licensing constraints, and integration requirements within NVIDIA-based AI development environments [^2][^7].
- Create a vector database integration strategy that combines spaCy tokenization, NumPy array operations, and semantic embedding storage to support retrieval-augmented generation (RAG) architectures in LLM applications [^2].
- Explain how Python natural language packages enable the transformer-based NLP techniques and deep learning model architectures covered in NVIDIA's official training curriculum for generative AI practitioners [^6].
Key concepts · tap to reveal
1/22·Idea
0%
Idea
01 / 22
When NLP Pipelines Break in Production
You're three days from a production deadline when your retrieval-augmented generation pipeline starts returning nonsensical answers. The vector database is running, the LLM endpoint is live, but somewhere between raw user queries and meaningful embeddings, the system is failing. You need to diagnose whether the issue lies in text preprocessing, numerical operations on embeddings, or the vector similarity search itself—and each layer depends on a different natural language processing package with distinct capabilities. Knowing which tool handles tokenization versus matrix operations versus semantic search isn't academic trivia; it's the difference between shipping on time and explaining to stakeholders why the AI feature they demoed last week no longer works.
Your task Write a prompt that asks Claude to recommend the right AI setup for a real task you're facing — then weigh its answer against this lesson, "Familiarity with the capabilities of Python natural language packages (spaCy, NumPy, vector databases, etc.).."
a strong prompt:role · context · task · format · example
Exercise · scenario
## Scenario **Difficulty Level: Applied** Your team is building a production **retrieval-augmented generation** (RAG) pipeline for an internal knowledge-base assistant. The lead architect has proposed using **spaCy** for named entity recognition on incoming queries, **NumPy** for **embedding** normalization, and a vector database for **semantic search** over 50,000 technical documents. During sprint planning, a junior developer suggests replacing spaCy with a custom regex parser "to save memory," using Python lists instead of NumPy arrays "because they're simpler," and storing embeddings in a relational database "since we already have PostgreSQL." The architect is on leave, and you must decide whether to approve these substitutions before the sprint begins. The exam objectives require familiarity with the capabilities of Python natural language packages including spaCy, NumPy, and **vector databases** [^1][^2]. **What would you do, and why?**
Deliverable
You will produce a **Python NLP Package Capability Matrix** as a markdown document that catalogs the core capabilities of **spaCy**, **NumPy**, and at least one vector database library (such as ChromaDB or Pinecone), aligned with the NVIDIA exam objective for familiarity with Python natural language packages[^1][^2].
Practice · Scenarios
0 of 8 revealed
Scenario 1 of 8
An e-commerce platform with 2 million product descriptions needs to implement semantic search where users can find products using natural language queries like 'waterproof hiking boots for winter'. The engineering team has generated 512-dimensional embeddings for all products using a sentence transformer model. They need a storage solution that supports approximate nearest neighbor search with sub-100ms query latency, handles concurrent read requests from 10,000+ users, provides filtering by metadata (price range, brand), and scales horizontally as the product catalog grows. The system must integrate with their Python-based recommendation engine.
Sources
- [1]NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide·NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide (2026) · Vendor
- [2]AWS Well-Architected Framework: Machine Learning Lens·AWS Well-Architected Framework: Machine Learning Lens (2026) · Vendor
Submit your work for review
Paste your capstone artifact below. You'll get back a 4-level rubric grade, per-criterion feedback, and three concrete edits to strengthen it.