0of23read0 XP
Build LLM use cases such as retrieval-augmented generation (RAG), chatbots, and summarizers.
Design a retrieval-augmented generation (RAG) pipeline that integrates external knowledge sources with an LLM to reduce hallucinations and ground responses in verifiable data [^1][^4].
- Time
- 20–25 min
- Type
- exercise
- Bloom
- Apply → Create
- XP
- 100
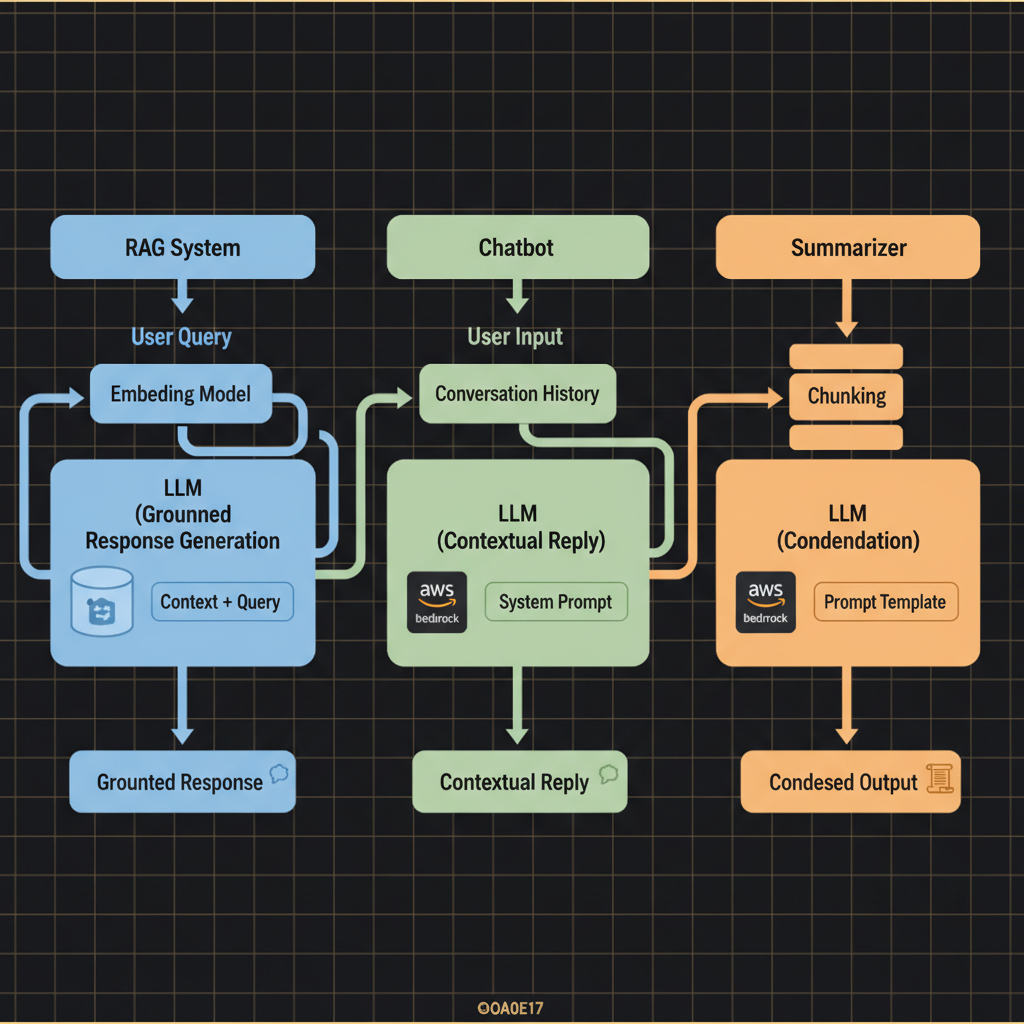
Architecture diagram for Build LLM use cases such as retrieval-augmented generation (RAG), chatbots, and summarizers.. Three parallel LLM use case architectures side by side. Left column: RAG system with user query flowing through embedding model to vector database retrieval, then context plus query feeding into LLM for grounded response. Middle column: Chatbot with conversation history buffer feeding into LLM with system prompt, producing contextual replies in a loop. Right column: Summarizer with long document input chunking through LLM to produce condensed output. Use distinct pastel colors for each use case (blue for RAG, green for chatbot, orange for summarizer). Label key components including vector stores, prompt templates, and response formatting. Show data flow with solid arrows and include AWS service icons where applicable (Bedrock, OpenSearch).
You'll be able to
- Design a retrieval-augmented generation (RAG) pipeline that integrates external knowledge sources with an LLM to reduce hallucinations and ground responses in verifiable data [^1][^4].
- Implement a conversational chatbot interface that maintains multi-turn dialogue context and applies RAG techniques to answer domain-specific questions accurately [^1][^5].
- Construct a summarization workflow using an LLM that condenses long-form documents or support case histories into concise, factually grounded outputs suitable for production environments [^1][^3].
- Evaluate the factual accuracy and relevance of RAG-based responses by comparing retrieval strategies (vector-based, graph-based, or hybrid) and selecting the approach that best fits your use case requirements [^6][^7].
- Apply LlamaIndex or equivalent context-augmentation frameworks to ingest, index, and query proprietary or domain-specific data sources, demonstrating proficiency in building NVIDIA-aligned LLM applications [^5].
Key concepts · tap to reveal
1/23·Idea
0%
Idea
01 / 23
The Production Reality of LLM Applications
You're a customer-support engineer at a fast-growing SaaS company, and your ticket queue just hit 3,000 open cases. Marketing launched a new product feature yesterday, and users are flooding in with questions your knowledge base doesn't yet cover. Your CEO asks if you can deploy a chatbot by end-of-week that answers questions accurately without inventing features that don't exist. The difference between a chatbot that hallucinates versus one grounded in your actual documentation can mean deflecting 70% of repetitive tickets or creating a PR crisis when users discover the bot recommended nonexistent workflows.
Your task Write a prompt that asks Claude to recommend the right AI setup for a real task you're facing — then weigh its answer against this lesson, "Build LLM use cases such as retrieval-augmented generation (RAG), chatbots, and summarizers.."
a strong prompt:role · context · task · format · example
Exercise · scenario
## Scenario **Difficulty level:** Applied Your team has been asked to build a customer-support assistant for an e-commerce platform that sells specialized industrial equipment. The platform maintains a large corpus of product manuals, troubleshooting guides, and past support tickets. Stakeholders want the assistant to answer technical questions accurately, avoid inventing product specifications, and handle multi-turn conversations where customers refine their questions. The engineering lead proposes three architectures: a pure **chatbot** (fine-tuned LLM with no external retrieval), a **retrieval-augmented generation** (**RAG**) pipeline that fetches relevant documents at query time, or a summarizer that pre-digests all manuals into a single condensed knowledge base. Research on e-commerce customer support indicates that **RAG** frameworks combining structured knowledge graphs with retrieved text can improve factual accuracy by 23 percent and achieve 89 percent user satisfaction in question-answering scenarios[^6]. Meanwhile, studies of RAG chatbots in education highlight that retrieval augmentation addresses the main barrier to LLM adoption: **hallucinations**[^4].
Deliverable
You will produce a **RAG Use-Case Implementation Portfolio** as a markdown document that specifies three distinct LLM applications aligned with the exam objective: one **retrieval-augmented generation** pipeline, one **chatbot**, and one summarizer [^1][^3].
Practice · Scenarios
0 of 8 revealed
Scenario 1 of 8
A legal firm handles complex merger and acquisition deals involving hundreds of contracts, each 50-200 pages long. Attorneys need to quickly understand key terms, obligations, and risk factors from these lengthy documents. The solution should take a single contract as input and produce a 2-3 page executive summary highlighting critical clauses, financial terms, termination conditions, and potential liabilities. The output must preserve legal accuracy and include page references to original clauses. The system will process one document at a time on-demand when attorneys upload files.
Quiz · adaptive · 3 items
Mastery check
Match each term to its definition. Pass at 80% to earn the lesson's XP and unlock the next.
Sources
- [1]OpenAlex API·OpenAlex API (2026) · Research
- [2]arXiv API·arXiv API (2026) · Research
- [3]NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide·NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide (2026) · Vendor
- [4]LlamaIndex Documentation·LlamaIndex Documentation (2026) · Vendor
- [5]arXiv API·arXiv API (2026) · Research
- [6]NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide·NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide (2026) · Vendor
Submit your work for review
Paste your capstone artifact below. You'll get back a 4-level rubric grade, per-criterion feedback, and three concrete edits to strengthen it.