0of19read0 XP
Familiarity with the fundamentals of machine learning (e.g., feature engineering, model comparison, cross validation).
Apply feature engineering techniques to prepare datasets for machine learning workflows, selecting and transforming input variables to improve model performance in generative AI contexts [^1][^2].
- Time
- 20–25 min
- Type
- exercise
- Bloom
- Apply → Create
- XP
- 100
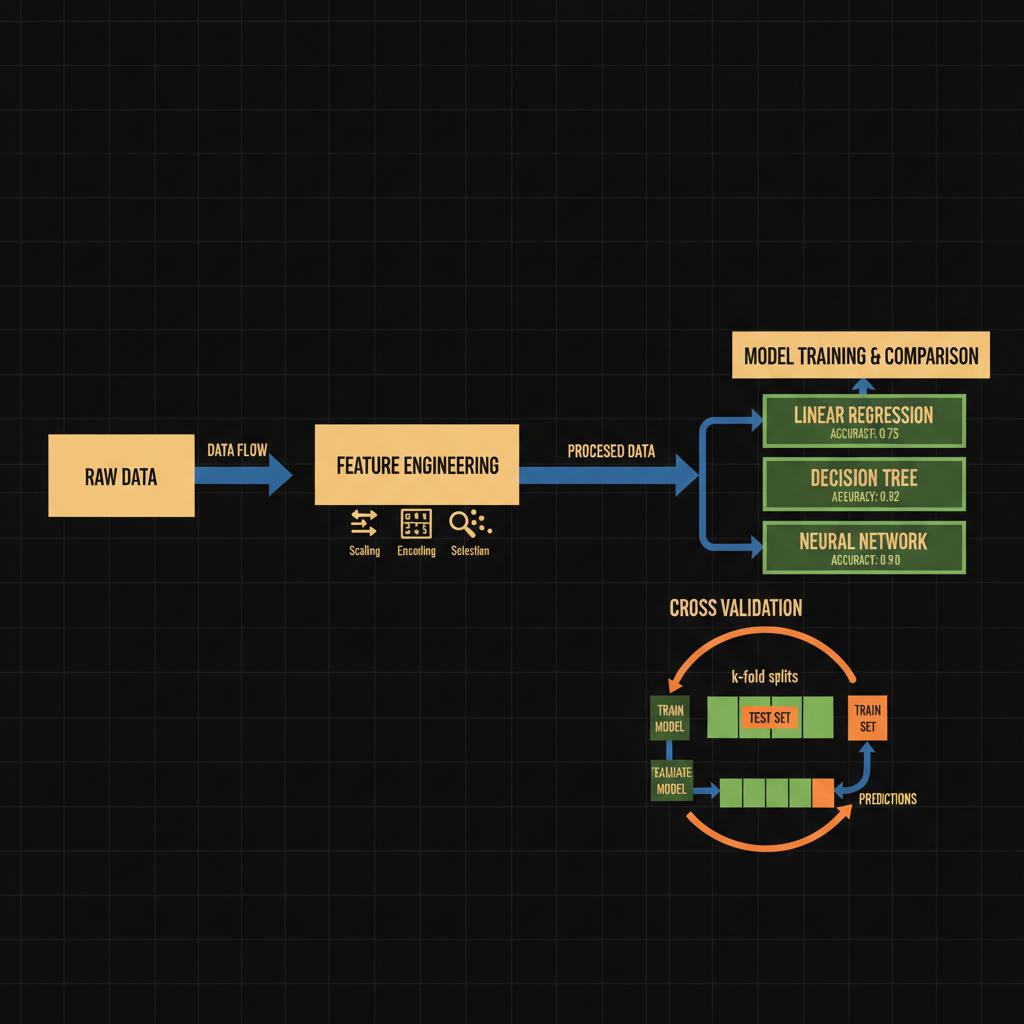
Architecture diagram for Familiarity with the fundamentals of machine learning (e.g., feature engineering, model comparison, cross validation).. The machine learning workflow with three main sequential phases connected by arrows. Start with "Raw Data" flowing into a "Feature Engineering" box (showing transformation icons for scaling, encoding, and selection). This feeds into a "Model Training & Comparison" section displaying three parallel model boxes (Linear Regression, Decision Tree, Neural Network) each with accuracy metrics. Below this, show a "Cross Validation" cycle with k-fold splits illustrated as segmented data blocks, with arrows indicating iterative train-test loops. Use blue for data flow, green for training processes, and orange for validation steps. Label each component clearly with technical terms.
You'll be able to
- Apply feature engineering techniques to prepare datasets for machine learning workflows, selecting and transforming input variables to improve model performance in generative AI contexts [^1][^2].
- Evaluate multiple machine learning models using systematic comparison methods, including cross-validation procedures, to determine which approach yields optimal results for a specific use case [^1][^2][^4].
- Implement cross-validation strategies to verify that models generalize well to new data and avoid overfitting, documenting experimental results and configurations throughout the process [^4][^5].
- Design model improvement experiments by establishing clear strategies for enhancement through data collection, hyperparameter tuning, and ensemble methods, progressing from baseline performance to optimized solutions [^4].
- Classify relationships and trends in experimental data that could affect machine learning research results, applying these insights to refine model selection and validation approaches [^3].
Key concepts · tap to reveal
1/19·Idea
0%
Idea
01 / 19
The Cost of Skipping ML Fundamentals
You're three days from deploying a sentiment-analysis model that will route 50,000 customer support tickets per day, and your manager asks: "How do we know it won't fall apart on next quarter's data?" You realize you never ran cross-validation, never compared your neural network against a simpler baseline, and never documented which features actually drive the predictions. The model works on your test set, but you have no systematic way to prove it will generalize, no record of what you tried, and no fallback if performance degrades in production.
Your task Write a prompt that asks Claude to recommend the right AI setup for a real task you're facing — then weigh its answer against this lesson, "Familiarity with the fundamentals of machine learning (e.g., feature engineering, model comparison, cross validation).."
a strong prompt:role · context · task · format · example
Exercise · scenario
## Scenario **Difficulty Level: Applied** You are a machine learning engineer at a company deploying a sentiment analysis model for customer feedback. Your initial model achieves 78% accuracy on the training set. Your manager asks you to improve performance before production deployment. You have three options: (1) engineer additional features from the text data, such as n-grams and part-of-speech tags; (2) compare your current logistic regression baseline against tree-based and neural architectures; or (3) implement k-fold **cross-validation** to better estimate how the model will generalize to unseen customer reviews [^1][^2]. Time and compute budget allow you to pursue only one strategy this sprint. **What would you do, and why?**
Deliverable
You will produce a **machine learning experiment comparison matrix** as a Markdown document that demonstrates systematic model evaluation using **feature engineering**, **cross-validation**, and performance comparison. The artifact should document at least three distinct model configurations applied to a single dataset, showing how you prepared features, split data for **cross-validation**, and compared results across algorithms or hyperparameter settings[^1][^2].
Practice · Scenarios
0 of 8 revealed
Scenario 1 of 8
An automotive manufacturer is building a predictive maintenance model for assembly line robots using sensor telemetry. The dataset contains 18 months of data from 200 robots across 3 factories. The ML team proposes splitting the data by time: months 1-12 for training, months 13-15 for validation, and months 16-18 for final testing. A senior engineer argues they should instead use k-fold splitting where each fold contains randomly sampled data from all time periods, ensuring every robot appears in multiple folds.
Quiz · adaptive · 3 items
Mastery check
Match each term to its definition. Pass at 80% to earn the lesson's XP and unlock the next.
Sources
- [1]AWS Well-Architected Framework: Machine Learning Lens·AWS Well-Architected Framework: Machine Learning Lens (2026) · Vendor
- [2]NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide·NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide (2026) · Vendor
- [3]NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide·NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide (2026) · Vendor
- [4]OpenAlex API·OpenAlex API (2026) · Research
Submit your work for review
Paste your capstone artifact below. You'll get back a 4-level rubric grade, per-criterion feedback, and three concrete edits to strengthen it.