0of18read0 XP
Familiarity with the capabilities of Python natural language packages (spaCy, NumPy, vector databases, etc.).
Classify the core capabilities of spaCy, NumPy, and vector databases according to their roles in natural language processing pipelines, distinguishing preprocessing, numerical computation, and semantic retrieval functions as specified in the NCA-GENL exam task body [^1].
- Time
- 20–25 min
- Type
- exercise
- Bloom
- Apply → Create
- XP
- 100
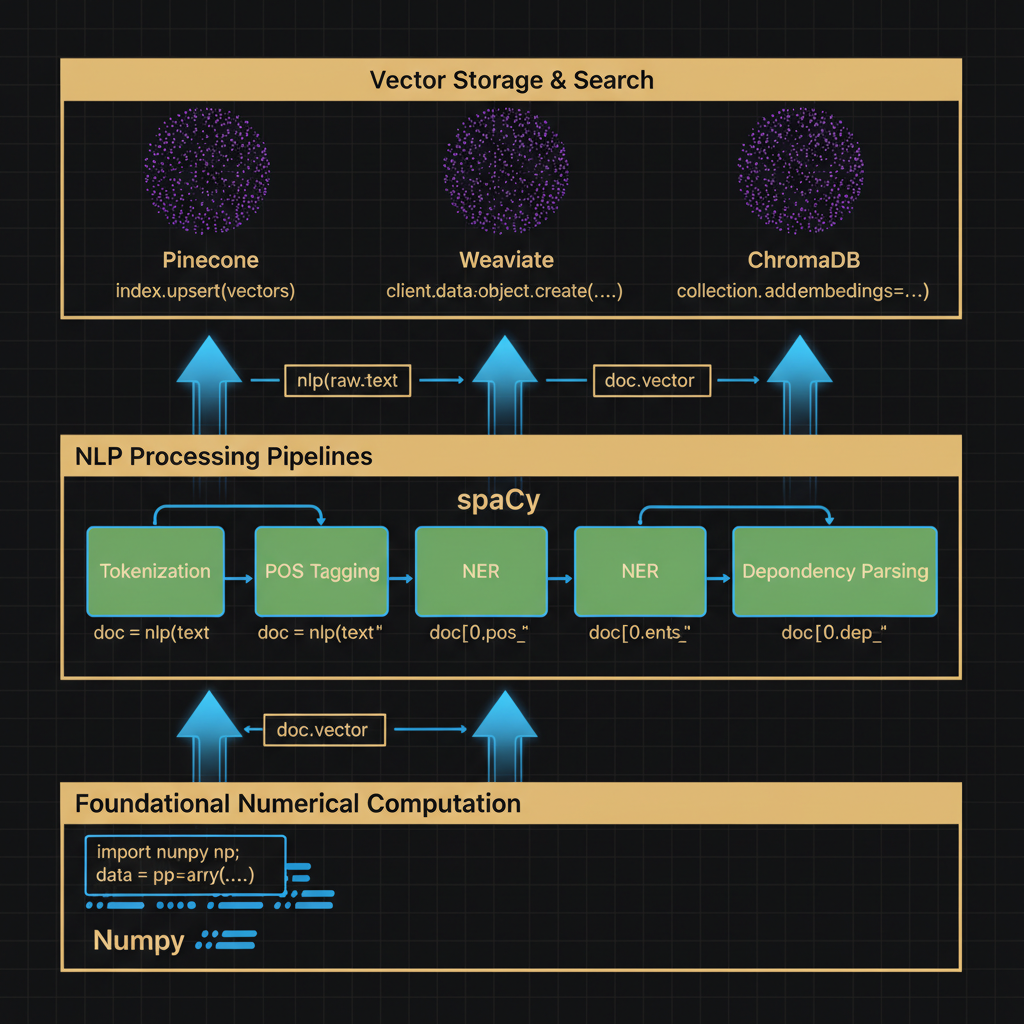
Architecture diagram for Familiarity with the capabilities of Python natural language packages (spaCy, NumPy, vector databases, etc.).. The Python NLP ecosystem stack. At the bottom layer, place NumPy as the foundational numerical computation library with array icons. Middle layer shows spaCy with components for tokenization, POS tagging, NER, and dependency parsing connected horizontally. Top layer displays vector databases (Pinecone, Weaviate, ChromaDB) storing embeddings as clustered points. Arrows flow upward showing data transformation from raw text through spaCy processing to vector storage. Include small code snippet boxes at transitions showing typical function calls. Use blue tones for data flow, green for processing components, and purple for storage. Label each component with primary capabilities in sans-serif text.
You'll be able to
- Classify the core capabilities of spaCy, NumPy, and vector databases according to their roles in natural language processing pipelines, distinguishing preprocessing, numerical computation, and semantic retrieval functions as specified in the NCA-GENL exam task body [^1].
- Apply Python natural language packages (spaCy, NumPy, Keras, and related libraries) to implement specific traditional machine learning analyses for text data in production environments [^4][^6].
- Evaluate the suitability of different Python NLP packages for a given generative AI use case by comparing their performance characteristics, integration requirements, and alignment with NVIDIA-recommended workflows for transformer-based natural language processing applications [^6].
- Create a working natural language processing workflow that integrates spaCy for linguistic feature extraction, NumPy for numerical operations on embeddings, and a vector database for semantic search, demonstrating familiarity with the capabilities required across Domain 1 and Domain 4 of the NCA-GENL certification [^1][^2].
Key concepts · tap to reveal
1/18·Idea
0%
Idea
01 / 18
Why Python NLP Package Familiarity Matters
You're three days from deploying a customer-support chatbot that must extract named entities from thousands of unstructured tickets, rank them by semantic similarity, and feed the results into a fine-tuned language model. The NVIDIA certification exam expects you to know which Python packages handle tokenization, which accelerate vector operations, and which store embeddings at scale. Choosing the wrong tool at this stage means rewriting your pipeline under deadline pressure, or worse, shipping a system that cannot meet production SLA requirements.
Your task Write a prompt that asks Claude to recommend the right AI setup for a real task you're facing — then weigh its answer against this lesson, "Familiarity with the capabilities of Python natural language packages (spaCy, NumPy, vector databases, etc.).."
a strong prompt:role · context · task · format · example
Exercise · scenario
## Scenario Your team is building a document classification pipeline for a financial services client who needs to extract named entities, perform sentiment analysis, and store document embeddings for **semantic search** across 500,000 regulatory filings. The client's existing proof-of-concept uses a mix of regex patterns and keyword matching, but accuracy has plateaued at 62%. Your manager asks you to recommend a Python stack that balances NLP capability, numerical computation performance, and vector storage for retrieval tasks, keeping in mind that the solution must integrate with the client's existing NVIDIA GPU infrastructure and support future LLM fine-tuning workflows[^1][^2]. The client expects a technical justification that references the specific capabilities of each package you propose.
Deliverable
You will produce a **Python NLP Capability Matrix** as a markdown document that catalogs the core capabilities of **spaCy**, **NumPy**, and at least one **vector database** library, mapped to the exam objectives in tasks 1.6 and 4.3[^1][^2]. For each package, document three capabilities with a one-sentence description, a minimal code snippet demonstrating the capability, and a citation to the relevant exam task.
Practice · Scenarios
0 of 8 revealed
Scenario 1 of 8
An e-commerce platform's recommendation engine receives user query embeddings (shape: 1x512) and must compute cosine similarity against 2 million product description embeddings stored in memory. The calculation requires normalizing vectors, computing dot products, and ranking results—all performed 10,000 times per second during peak traffic. The infrastructure team needs the mathematical operations to leverage CPU vectorization for maximum throughput. Which package provides the foundational array operations for this computation?
Sources
- [1]NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide·NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide (2026) · Vendor
- [2]NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide·NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide (2026) · Vendor
- [3]AWS Well-Architected Framework: Machine Learning Lens·AWS Well-Architected Framework: Machine Learning Lens (2026) · Vendor
Submit your work for review
Paste your capstone artifact below. You'll get back a 4-level rubric grade, per-criterion feedback, and three concrete edits to strengthen it.