0of18read0 XP
Identify relationships and trends or any factors that could affect the results of research.
Evaluate experimental design choices—including data augmentation strategies, model selection, and validation approaches—that influence the reliability and generalizability of generative AI research outcomes [^1][^3].
- Time
- 20–25 min
- Type
- exercise
- Bloom
- Apply → Create
- XP
- 100
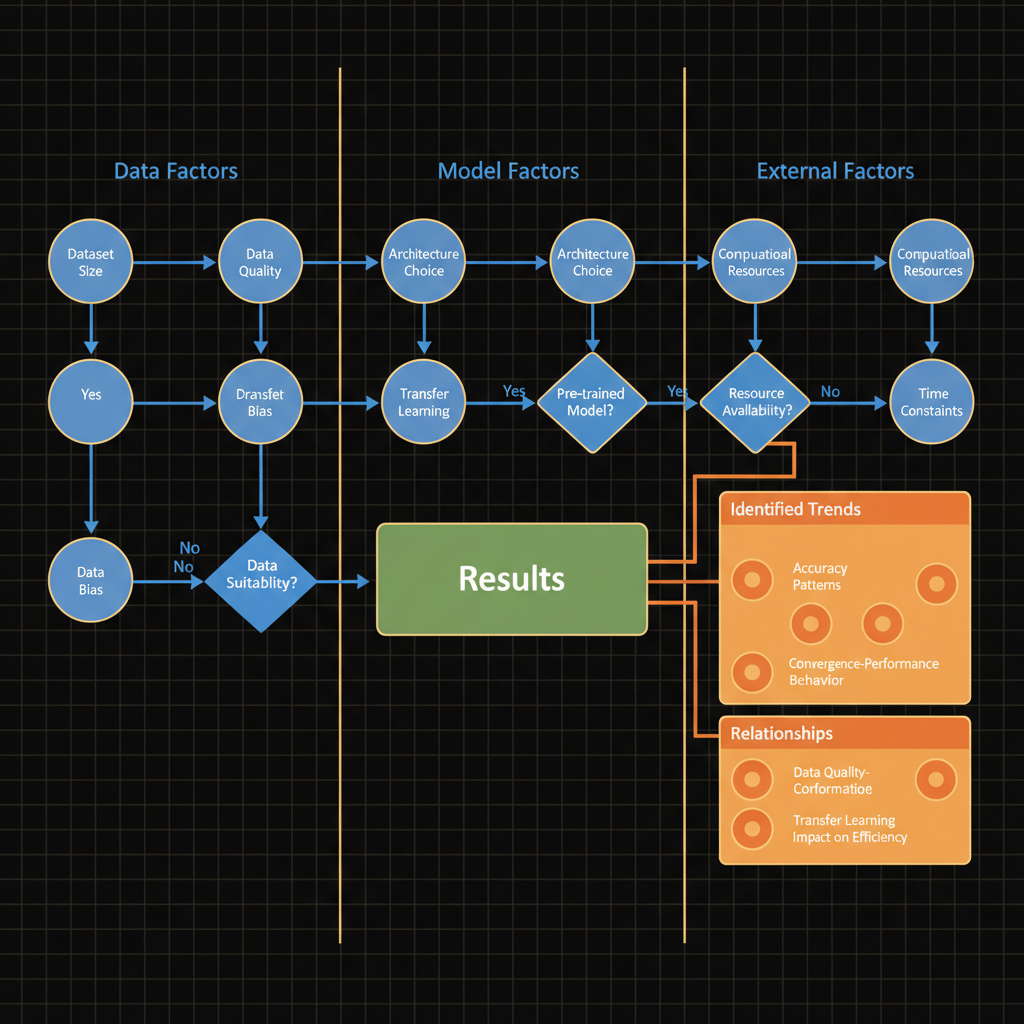
Architecture diagram for Identify relationships and trends or any factors that could affect the results of research.. The research analysis process for deep learning model evaluation. The diagram should flow left to right with three main columns: Data Factors (showing dataset size, quality, and bias nodes), Model Factors (showing architecture choice, hyperparameters, and transfer learning applicability), and External Factors (showing computational resources and time constraints). Use arrows to connect these factor groups to a central Results node, then branch to Identified Trends (accuracy patterns, convergence behavior) and Relationships (correlation between data quality and performance, impact of transfer learning on efficiency). Color code factor categories in blue, results in green, and analysis outputs in orange. Include decision diamond shapes where factors create conditional paths affecting research outcomes.
You'll be able to
- Evaluate experimental design choices—including data augmentation strategies, model selection, and validation approaches—that influence the reliability and generalizability of generative AI research outcomes [^1][^3].
- Apply transformer-based model comparison techniques to identify performance trends across text classification, named-entity recognition, and question-answering tasks, citing quantitative metrics and corpus characteristics that affect results [^1][^3].
- Classify confounding factors in LLM experimentation, such as dataset size, domain shift, and hyperparameter sensitivity, and explain how each factor alters inference accuracy or training convergence [^1][^3].
- Create a documented analysis workflow using cuDF, NetworkX, or LangChain orchestration to surface relationships between input features and model behavior, demonstrating proficiency with NVIDIA-accelerated data-science tooling [^1][^3].
- Evaluate A/B testing and cross-validation results to determine whether observed performance differences stem from algorithmic improvements, data quality variations, or environmental factors, and justify your conclusion with evidence from experimental logs [^1][^3].
Key concepts · tap to reveal
1/18·Idea
0%
Idea
01 / 18
When Production Diverges from Benchmarks
You deploy a question-answering model that achieves 92% accuracy on benchmark datasets. Three weeks into production, users report failures on industry-specific jargon, hallucinations when context is ambiguous, and degraded performance during peak traffic hours when inference latency exceeds 200 milliseconds. The model hasn't changed, but real-world factors—vocabulary drift, prompt variability, hardware load—are quietly reshaping your results in ways initial experiments never anticipated.
Your task Write a prompt that asks Claude to recommend the right AI setup for a real task you're facing — then weigh its answer against this lesson, "Identify relationships and trends or any factors that could affect the results of research.."
a strong prompt:role · context · task · format · example
Exercise · scenario
## Scenario **Difficulty Level: Applied** You are fine-tuning a BERT-based **named-entity recognition** model for a legal document processing pipeline. After three training runs, you notice that validation F1 scores plateau at 0.78, but when you test the model on a held-out set of contracts from a different jurisdiction, performance drops to 0.61. Your manager asks whether you should proceed with deployment or investigate further. The training corpus was drawn exclusively from California case law, while the production environment will process documents from multiple U.S. states and federal courts. You have access to cuDF for exploratory data analysis[^3] and LangChain for orchestrating additional data pipelines[^1], but limited time before the deployment deadline. **What would you do, and why?** In your answer, identify at least two factors that could affect research results and explain how you would use available tools to confirm or rule out each hypothesis.
Deliverable
You will produce a **Markdown research-factor analysis document** that examines one generative-AI experiment or model-evaluation scenario relevant to your work. The document must identify at least three relationships, trends, or confounding factors that could affect experimental results, drawing on the techniques NVIDIA recommends for identifying such factors: **data augmentation** effects on model accuracy, transfer-learning dependencies, A/B testing design, **cross-validation** strategy, or prompt-engineering workflow composition[^1][^3].
Practice · Scenarios
0 of 8 revealed
Scenario 1 of 8
A financial services firm develops a sentiment analysis model to predict stock price movements from earnings call transcripts. The model is trained on transcripts from Fortune 500 companies and achieves 78% accuracy on held-out test data from similar large-cap firms. When applied to small-cap technology startups, accuracy falls to 52%. Investigation shows that small-cap transcripts average 12 minutes in length versus 45 minutes for Fortune 500 calls, contain more technical jargon specific to emerging technologies, and exhibit different linguistic patterns (more informal, frequent use of industry slang). The model architecture and hyperparameters remain unchanged.
Quiz · adaptive · 3 items
Mastery check
Match each term to its definition. Pass at 80% to earn the lesson's XP and unlock the next.
Sources
- [1]NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide·NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide (2026) · Vendor
- [2]NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide·NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide (2026) · Vendor
- [3]OpenAlex API·OpenAlex API (2026) · Vendor
Submit your work for review
Paste your capstone artifact below. You'll get back a 4-level rubric grade, per-criterion feedback, and three concrete edits to strengthen it.