0of21read0 XP
Awareness of the process of extracting insights from large datasets using data mining, data visualization, and similar techniques.
Apply data mining and visualization techniques to extract actionable insights from large-scale datasets in generative AI workflows, demonstrating awareness of the processes required by the NVIDIA certification exam [^1].
- Time
- 20–25 min
- Type
- exercise
- Bloom
- Understand → Create
- XP
- 100
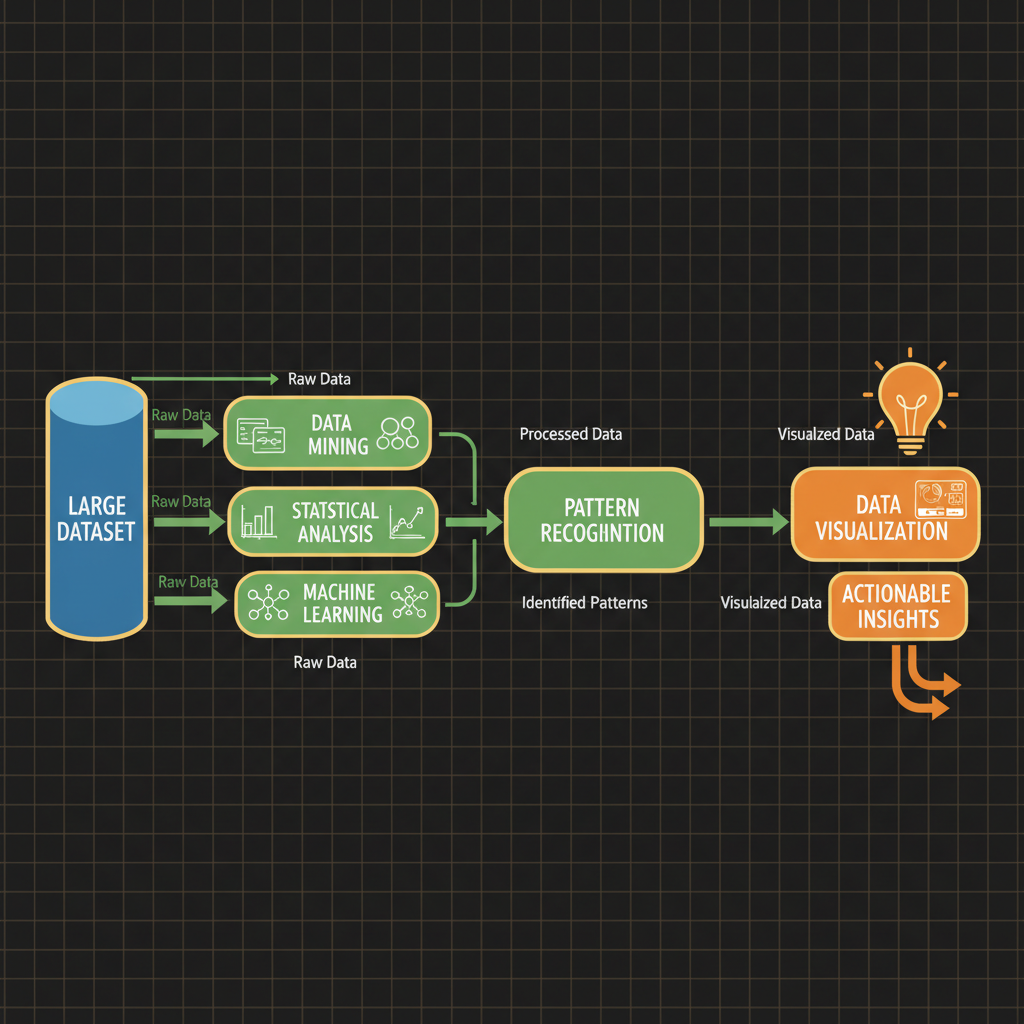
Architecture diagram for Awareness of the process of extracting insights from large datasets using data mining, data visualization, and similar techniques.. The data insight extraction pipeline from left to right. Begin with a cylinder representing "Large Dataset" feeding into three parallel processing branches: "Data Mining" (with association rules and clustering icons), "Statistical Analysis" (with graph symbols), and "Machine Learning" (with neural network node). These branches converge into a "Pattern Recognition" box, then flow to "Data Visualization" (showing dashboard elements like charts and graphs), and finally terminate at "Actionable Insights" (lightbulb icon with decision arrows). Use blue for data storage, green for processing steps, and orange for output stages. Include small arrows labeled with data types between each major component.
You'll be able to
- Apply data mining and visualization techniques to extract actionable insights from large-scale datasets in generative AI workflows, demonstrating awareness of the processes required by the NVIDIA certification exam [^1].
- Evaluate the effectiveness of different visualization methods (such as tag clouds, heat maps, and graphs) for representing complex relationships and patterns discovered through data mining operations [^6].
- Create visual representations of time-series or high-dimensional data that reveal temporal dynamics, anomalies, and optimization opportunities relevant to AI model training and deployment [^5].
- Classify data mining outputs and visualization artifacts according to their suitability for specific insight-extraction tasks across the machine learning pipeline, data analysis, and experimentation domains [^1][^2][^3].
- Explain how semantic extraction, indexing, and parameter reduction operations transform raw datasets into interpretable visual formats that support discovery of novel inferences in large-scale AI projects [^6].
Key concepts · tap to reveal
1/21·Idea
0%
Idea
01 / 21
The Dark Room Problem
You're three weeks into building a generative AI pipeline for customer support when your stakeholder asks: "Why is the model hallucinating product names that don't exist?" You have 200 GB of chat logs, embeddings scattered across vector stores, and a dashboard showing accuracy drifting downward each week. Without the skill to surface signal buried in that noise, to turn raw data into a diagnosis you can act on, and to visualize patterns that explain model behavior, you're troubleshooting in the dark.
Your task Write a prompt that asks Claude to recommend the right AI setup for a real task you're facing — then weigh its answer against this lesson, "Awareness of the process of extracting insights from large datasets using data mining, data visualization, and similar techniques.."
a strong prompt:role · context · task · format · example
Exercise · scenario
## Scenario **Difficulty Level:** Applied You are a machine learning engineer at a renewable-energy startup that has deployed IoT sensors across 200 commercial buildings to monitor power consumption. After six months, you have accumulated 15 TB of timestamped energy readings. Your VP of Product asks you to identify which buildings exhibit recurring consumption **anomalies** and to recommend efficiency improvements for the top ten outliers. The raw CSV files are stored in cloud object storage, and your team has access to GPU-accelerated compute for model training. You must decide whether to build a custom anomaly-detection pipeline using traditional **data mining** and visualization methods, or to fine-tune a vision-based large language model on graphical representations of the **time-series data**, as described in recent research on building energy analytics[^5]. **What would you do, and why?** Justify your approach by explaining which techniques for extracting insights from large datasets[^1][^2][^3] best suit the startup's need for both interpretability and scalability, and describe how you would validate that your chosen method produces actionable recommendations.
Deliverable
You will produce a **Data Insight Extraction Playbook** as a Markdown document that demonstrates your awareness of the process of extracting insights from large datasets using **data mining**, **data visualization**, and similar techniques[^1][^2][^3].
Practice · Scenarios
0 of 8 revealed
Scenario 1 of 8
A pharmaceutical research team analyzes clinical trial data from 15,000 patients across 40 sites, including genomic sequences, lab results, and adverse event reports. They apply association rule mining to identify correlations between genetic markers and treatment responses, then use decision trees to segment patient populations by response likelihood. The team produces scatter plots and box plots to validate findings, and creates a final presentation with bar charts summarizing the discovered patient segments and their characteristics.
Sources
- [1]NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide·NVIDIA-Certified Associate: Generative AI LLMs (NCA-GENL) Study Guide (2026) · Vendor
- [2]arXiv API·arXiv API (2026) · Research
- [3]arXiv API·arXiv API (2026) · Research
- [4]NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide·NVIDIA-Certified Associate: Generative AI Multimodal (NCA-GENM) Study Guide (2026) · Vendor
- [5]arXiv API·arXiv API (2026) · Research
- [6]OpenAlex API·OpenAlex API (2026) · Vendor
Submit your work for review
Paste your capstone artifact below. You'll get back a 4-level rubric grade, per-criterion feedback, and three concrete edits to strengthen it.